Introduction
Lors de mon stage de deuxième année, j’ai eu la chance de rejoindre à nouveau l’unité du DRN de Nantes Métropole. Le projet qui m’a été confié portait sur l’automatisation massive de la mise à jour du firmware des switchs.
L’infrastructure gérée par l’équipe couvre plus de 400 sites répartis dans toute la ville. Dans ce contexte, les mises à jour logicielles représentent une opération sensible et chronophage lorsqu’elles sont réalisées manuellement. L’objectif du projet était donc de concevoir une solution fiable permettant d’industrialiser ce processus tout en limitant les risques liés à l’administration de masse.
Automatisation avec Ansible et NetBox
La solution développée repose sur l’utilisation d’Ansible pour l’automatisation et de NetBox comme source centrale d’inventaire. NetBox est un outil « source de vérité » permettant de faire l’inventaire exhaustif de son parc informatique. Ayant travaillé sur Netbox lors de mon stage de 1ère année ce projet s’inscrit dans la continuité de ce que j’ai pu accomplir avec l’équipe du DRN.
Création du playbook : Un inventaire dynamique
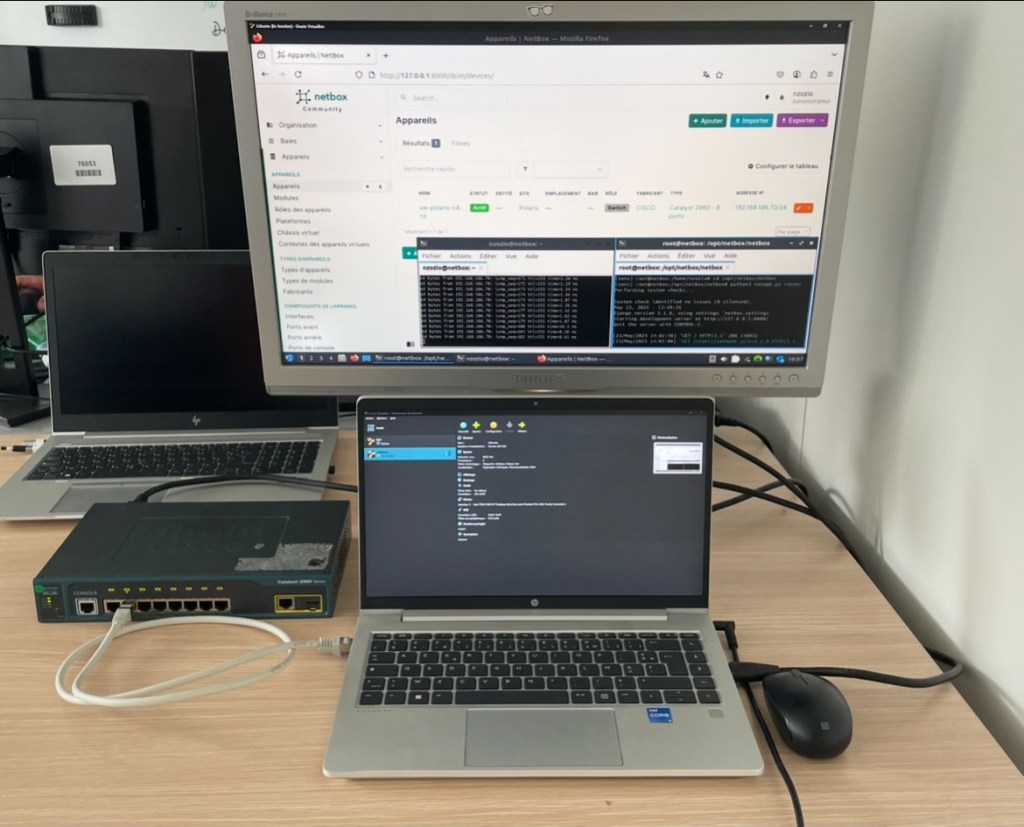
Grâce au plugin d’inventaire dynamique netbox.netbox.nb_inventory, les informations des équipements concernés sont récupérées via une API (REST) selon plusieurs critères définis dans NetBox. L’inventaire utilisé par le playbook est ainsi généré directement à partir des données présente dans NetBox, ce qui permet de travailler sur un parc d’équipements cohérent et toujours à jour.
Avant toute intervention sur l’environnement de production, j’ai mis en place un laboratoire de test afin de reproduire une architecture proche de celle utilisée par l’équipe réseau. Cet environnement comprenait une machine Linux exécutant Ansible, une instance NetBox et un switch Cisco utilisé pour les expérimentations. Cette phase m’a permis de valider l’intégration entre les différents composants et de tester les modules réseau fournis par Ansible.
Fonctionnement du playbook
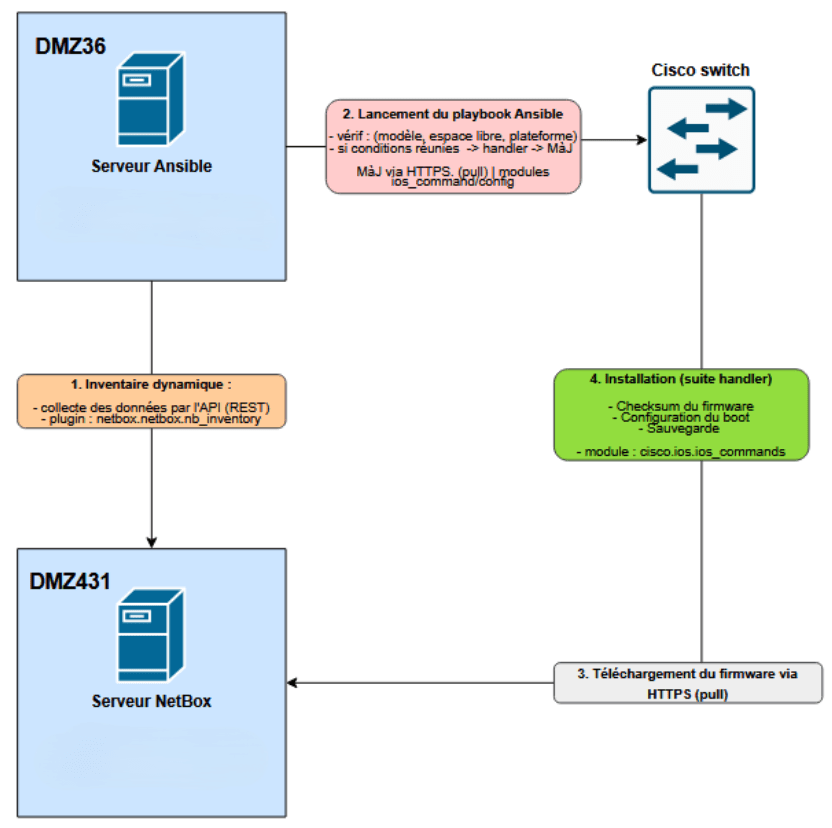
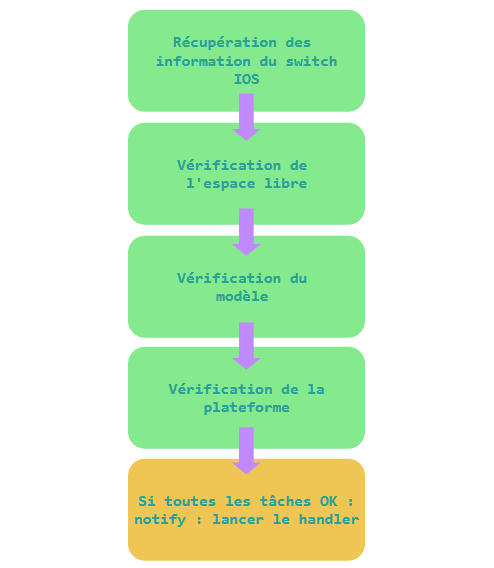
Le cœur du projet repose sur un playbook chargé d’orchestrer le processus de mise à jour. Lors de son exécution, Ansible se connecte aux équipements via SSH en utilisant le mode network_cli. Le playbook commence par récupérer les informations matérielles du switch grâce au module ios_facts.
Ces informations permettent de vérifier que le modèle détecté correspond bien à celui référencé dans NetBox. En cas d’incohérence, l’exécution du playbook est interrompu afin d’éviter toute mise à jour sur un équipement incorrect. Une seconde vérification concerne l’espace disponible dans la mémoire flash du switch. Le playbook extrait les informations du système de fichiers et compare l’espace libre avec la taille de l’image firmware à installer.
Lorsque toutes les conditions sont réunies, un handler est déclenché afin de lancer les étapes de transfert et d’installation du firmware. Cette organisation permet de séparer clairement les phases de vérification et les actions critiques.
Détail du fichier d’inventaire : ios15.2_7_E12_inventory.yml
Détail des taches du playbook : iosE12_firmware_update.yml
Détail des taches du handler : handler.yml
Choix du protocole de transfert du firmware
Une partie importante du projet a consisté à déterminer la méthode la plus fiable pour transférer les images firmware vers les switchs. Plusieurs scénarios ont été étudiés autour du protocole SCP, en mode push et pull, avec le switch configuré comme serveur dans certains cas. Ces tests ont cependant révélé plusieurs limites. Selon les modèles, les switchs Cisco gèrent difficilement le rôle de serveur SCP, notamment en raison de contraintes matérielles et logicielles. De plus, cette architecture nécessitait l’ouverture de flux spécifiques sur le pare-feu afin de permettre les échanges avec la machine Ansible, ce qui augmentait indirectement la surface d’attaque de l’infrastructure.
Afin de simplifier l’architecture et de limiter les risques de sécurité, la solution retenue a finalement été le téléchargement du firmware via HTTPS en mode client. Dans ce modèle, le switch récupère directement l’image depuis un serveur web, en utilisant un flux déjà autorisé sur l’infrastructure. Cette approche s’est révélée plus simple à maintenir et plus cohérente avec les exigences de sécurité du réseau.
Gestion des contraintes liées au protocole SSH
Lors du développement du playbook, certaines difficultés sont apparues lors de la connexion aux équipements réseau. Plusieurs modèles de switchs utilisent encore des clés d’algorithmes de chiffrement SSH anciennes qui ne sont plus activées par défaut sur les systèmes récents. Cette incompatibilité empêchait Ansible d’établir correctement les connexions avec certains équipements.
Pour résoudre ce problème, le mode de connexion network_cli a été utilisé. Celui-ci s’appuie directement sur la configuration OpenSSH de la machine exécutant Ansible. Il a donc été nécessaire d’adapter cette configuration afin de permettre la prise en charge des algorithmes requis par certains équipements plus anciens.
Résultat du projet
Une attention particulière a été portée à la sécurisation du processus. Les différentes vérifications intégrées au playbook garantissent que les mises à jour ne sont exécutées que lorsque l’état de l’équipement correspond exactement aux conditions attendues.
À l’issue du stage, le playbook était fonctionnel. Il constitue désormais une base solide pour automatiser la gestion des mises à jour du parc de switchs de Nantes Métropole et démontre l’intérêt de l’automatisation pour l’administration d’infrastructures réseau à grande échelle. Il servira également de template afin de de mettre à jour d’autres versions de firmware Cisco.
Conclusion
Ce stage m’a permis de travailler sur un projet concret d’automatisation réseau dans un environnement professionnel réel. Le développement du playbook Ansible et son intégration avec NetBox m’ont confronté aux enjeux de fiabilité, de sécurité et de gestion d’infrastructures à grande échelle.
Cette expérience a renforcé mes compétences en automatisation et en administration réseau, tout en me donnant une meilleure compréhension des contraintes opérationnelles liées à la gestion d’un parc important d’équipements.





















{kind=link}